Loren Mur-Labadia
lmur@unizar.es

I am Lorenzo Mur-Labadia, a final-year PhD researcher in Deep Learning and Computer Vision at the University of Zaragoza (Spain), supervised by Prof. Rubén Martínez-Cantín and Prof. Josechu Guerrero.
My research focuses on video understanding, video–language learning, and 4D scene representations; with applications to embodied and egocentric perception.
During my PhD, I developed visual models for segmentation, detection, forecasting, and representation learning, leading to six first-author publications at top-tier computer vision venues, including ICRA 2023, ICCV 2023, IROS 2023, ECCV 2024, CVPR 2025, ICCV 2025 and 2 journals (CVIU and T-PAMI).
In the last 6 months, I was a Research Scientist intern at Meta AI (FAIR) in Paris, where I work with Adrien Bardes and Yann LeCun on large-scale self-supervised video understanding.
News
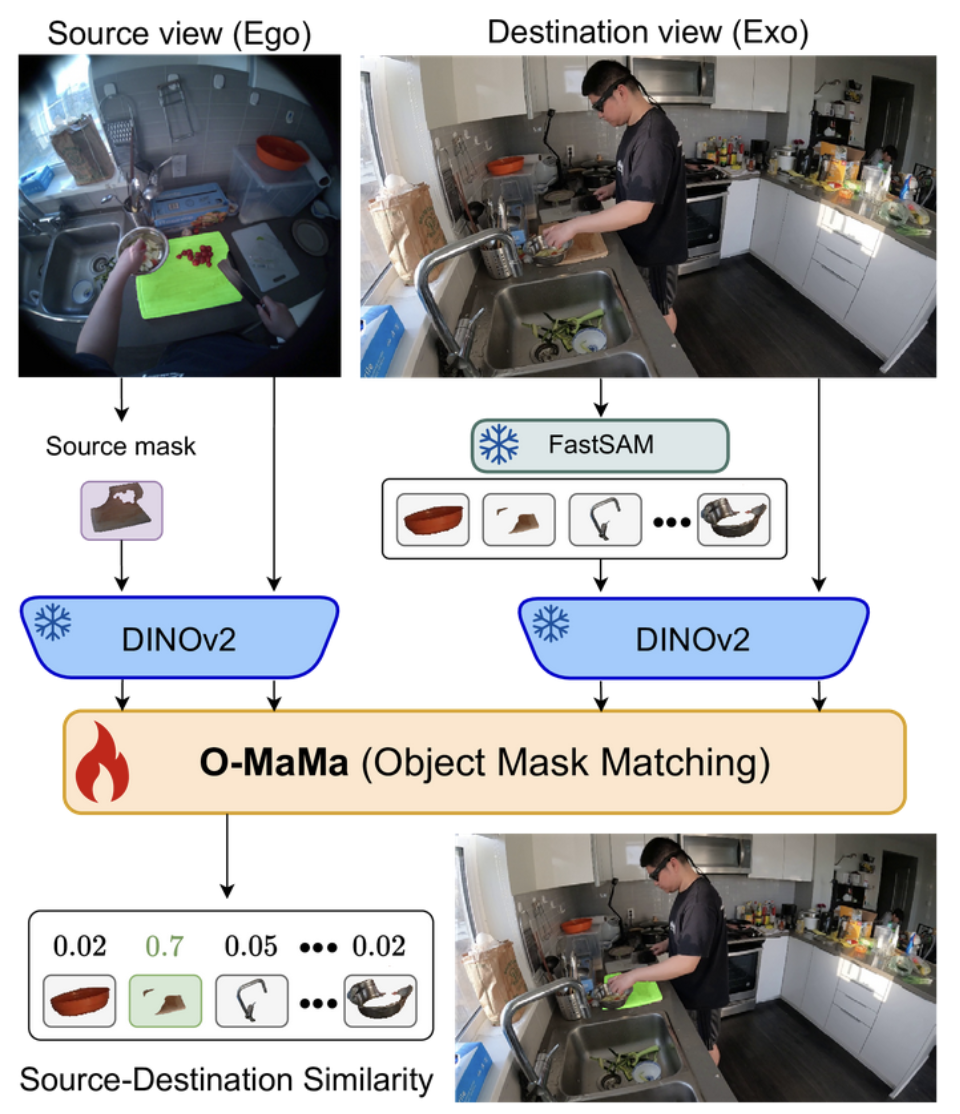
| Jun 10, 2025 | O-MaMa won the EgoVIS Object Correspondences Challenge at CVPR 2025. |
|---|---|
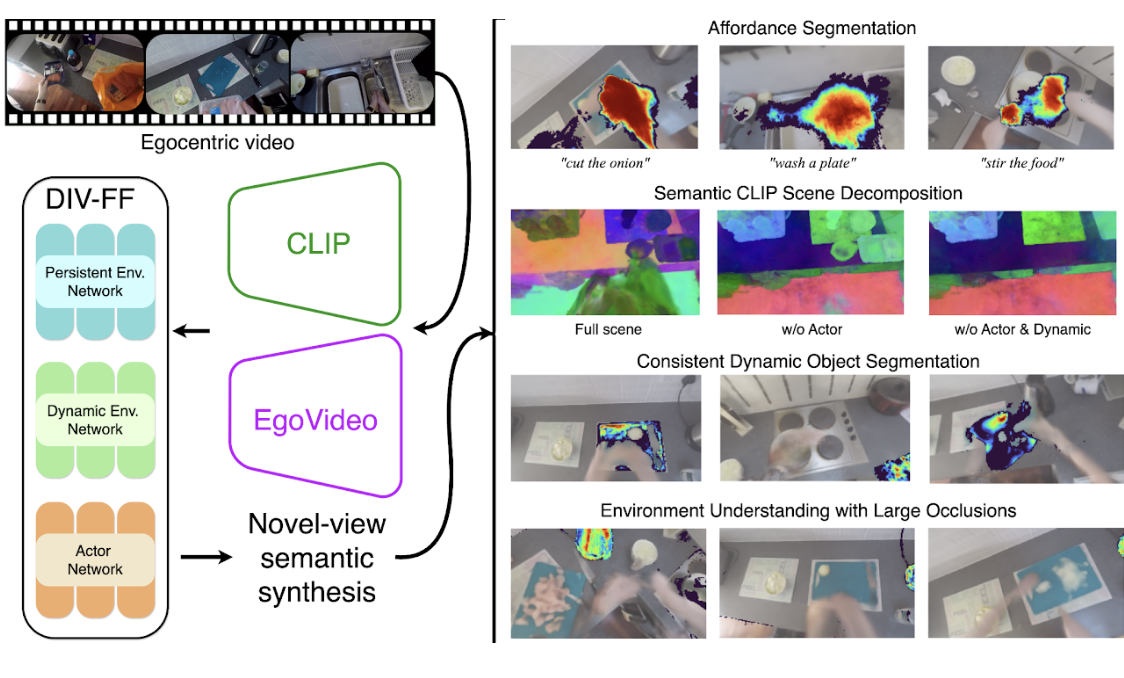
| Mar 11, 2025 | DIV-FF: Dynamic Image-Video Feature Fields for Environment Understanding in Egocentric Videos was accepted at CVPR 2025 as a Highlight. |
| Jul 04, 2024 | I participated in ICVSS 2024, held in Sicily. |
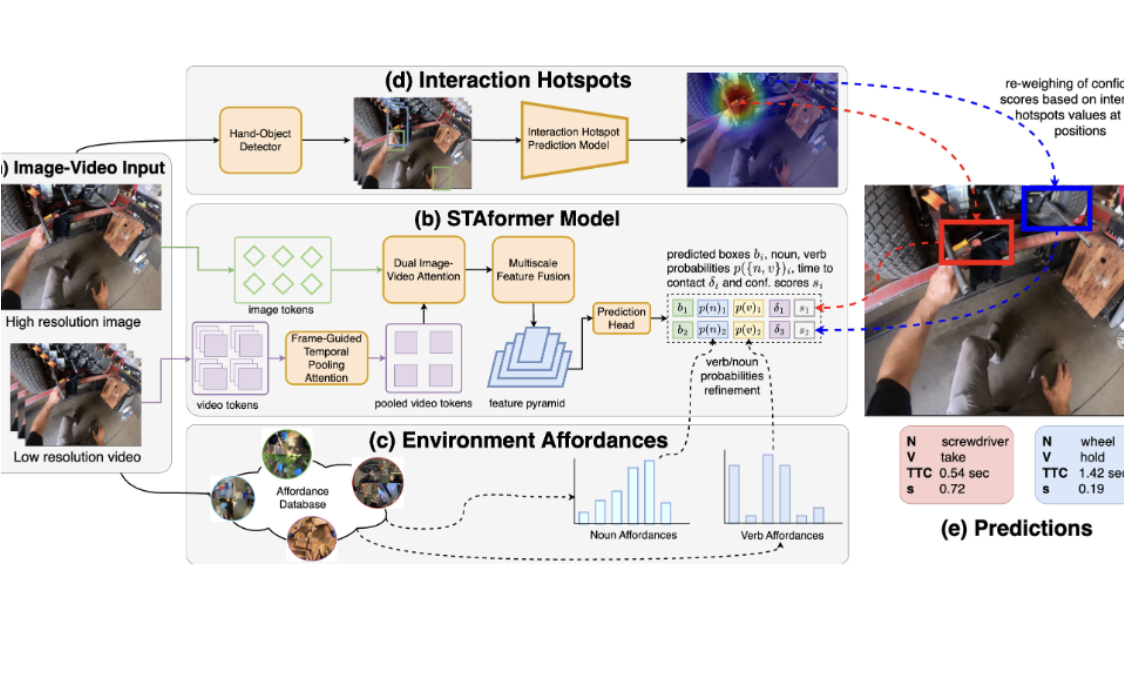
| Jul 01, 2024 | AFF-ttention! Affordances and Attention Models for Short-Term Object Interaction Anticipation, developed at the University of Catania with A. Furnari and G. M. Farinella, was accepted at ECCV 2024. |
| Jun 17, 2024 | I attended CVPR 2024 in Seattle, presenting two winning solutions from the Ego4D Challenge. Bayesian temporal-order priors for test-time refinement, in collaboration with C. Plou, won 1st Prize at the EgoVIS Step Grounding Challenge. AFF-ttention! Affordances and Attention Models for Short-Term Object Interaction Anticipation won 2nd Prize at the EgoVIS Short-Term Anticipation Challenge. |
| Nov 15, 2023 | I was invited to the 3rd NAVER International Workshop on AI for Robotics. |
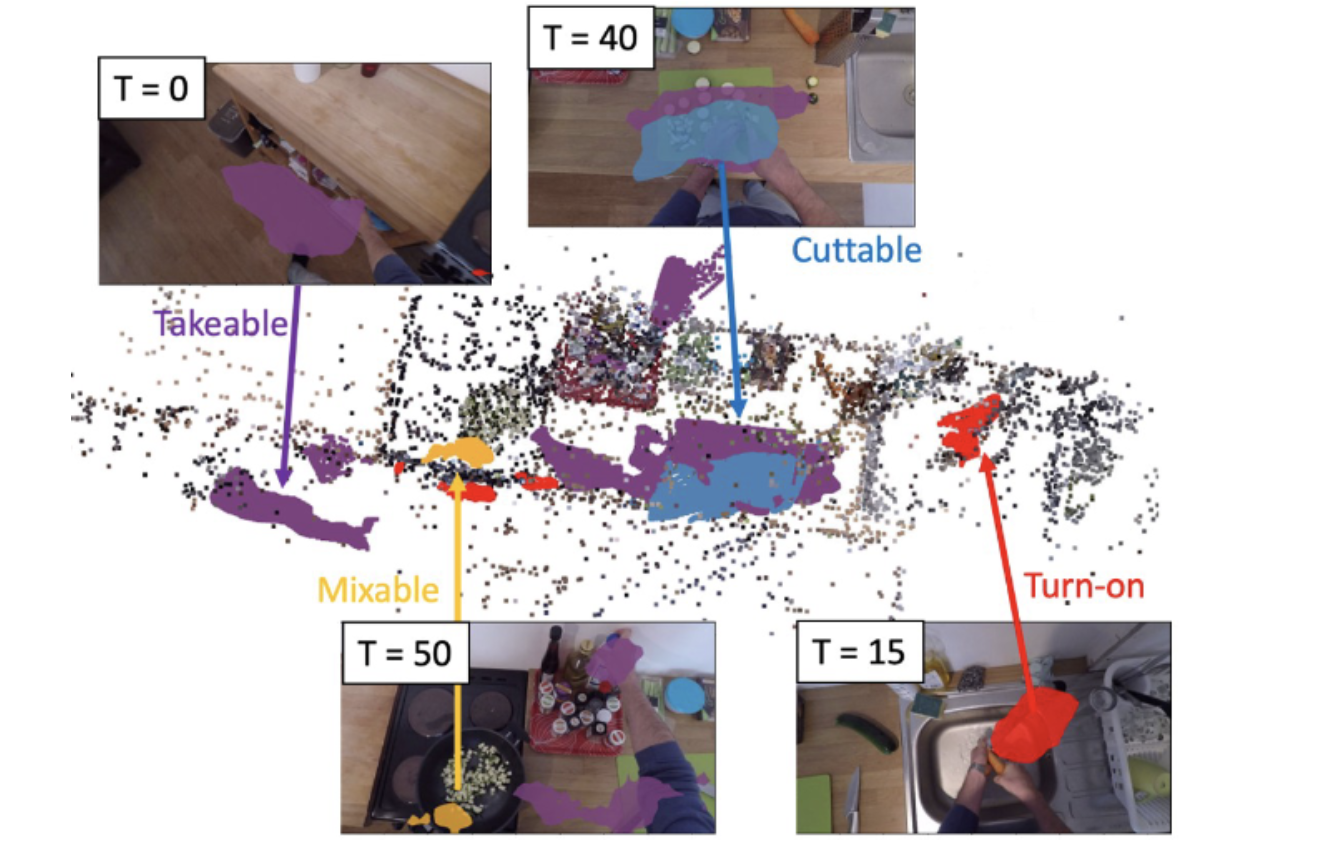
| Sep 06, 2023 | I attended ICCV 2023 in Paris, presenting Multi-label Affordance Mapping from Egocentric Vision. |
Publications
- Q2 JOURNAL
 Temporal video segmentation with natural language using text-video cross attention and Bayesian order-priorsComputer Vision and Image Understanding (CVIU), 2025
Temporal video segmentation with natural language using text-video cross attention and Bayesian order-priorsComputer Vision and Image Understanding (CVIU), 2025 - Q2 JOURNAL
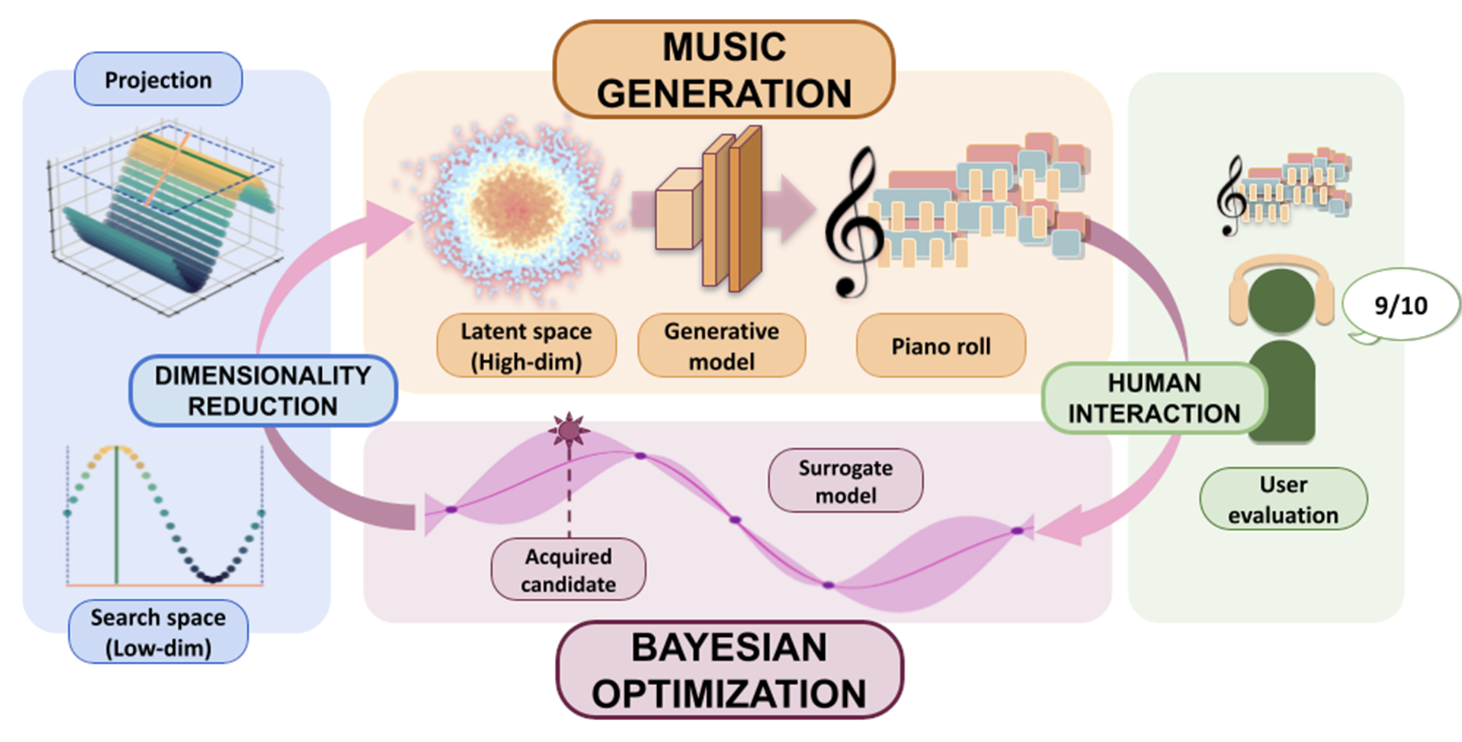 Random rotational embedding Bayesian optimization for human-in-the-loop personalized music generationPloS one Journal, 2025
Random rotational embedding Bayesian optimization for human-in-the-loop personalized music generationPloS one Journal, 2025